 Java10 - 新特性
Java10 - 新特性
笔记
Java 10 虽然新特性有 109 个,但是对于开发人员才说,真正能体验的新特性只有一个。
本内容涉及实际编写代码的是局部变量类型推断和新增不可变集合方法。
2022-02-08 @Young Kbt
# Java10概述
2018 年 3 月 21 日,Oracle 官方宣布 Java 10 正式发布。
需要注意的是 Java 9 和 Java 10 都不是 LTS(Long-Term-Support)版本。和过去的 Java 大版本升级不同,这两个只有半年左右的开发和维护期。而未来的 Java 11,也就是1 8.9 LTS,才是 Java 8 之后第一个 LTS 版本。
JDK10 一共定义了 109 个新特性,其中包含 12 个 JEP(对于程序员来讲,真正的新特性其实就一个),还有一些新 API 和 JVM 规范以及 JAVA 语言规范上的改动。
JDK 10 的 12 个 JEP (JDK Enhancement Proposal 特性加强提议),参阅官方文档: http://openjdk.java.net/projects/jdk/10/
# Java10的12个JEP
- 286:Local-Variable Type lnference 局部变量类型推断
- 296:Consolidate the JDK Forest into a Single Repository JDK 库的合并
- 304:Garbage-Collector Interface 统一的垃圾回收接口
- 307:Parallel Full GC for G1 为 G1 提供并行的 Full GC
- 310:Application Class-Data Sharing 应用程序类数据(AppCDS)共享
- 312:Thread-Local Handshakes ThreadLocal 握手交互
- 313:Remove the Native-Header Generation Tool (javah)移除 JDK 中附带的 javah 工具
- 314:Additional Unicode Language-Tag Extensions 使用附加的 Unicode 语言标记扩展
- 316:Heap Allocation on Alternative Memory Devices 能将堆内存占用分配给用户指定的备用内存设备
- 317:Experimental Java-Based JIT Compiler 使用基于 Java 的 JIT 编译器
- 319:Root Certificates 根证书
- 322:Time-Based Release Versioning 基于时间的发布版本
# 局部变量类型推断
# 产生背景
开发者经常抱怨 Java 中引用代码的程度。局部变量的显示类型声明,常常被认为是是不必须的,给一个好听的名字经常可以很清楚的表达出下面应该怎样继续。
好处:
- 减少了啰嗦和形式的代码,避免了信息冗余,而且对齐了变量名,更容易阅读
举例如下:
场景一:类实例化时
作为 Java 开发者,在声明一个变量时,我们总是习惯了敲打两次变量类型,第一次(左侧)用于声明变量类型,第二次(右侧)用于构造器。
LinkedHashSet<Integer> set = new LinkedHashSet<>();1场景二:返回值类型含复杂泛型结构
变量的声明类型书写复杂且较长,尤其是加上泛型的使用
Iterator<Map.Entry<Integer, Student>> iterator = set.iterator();1场景三:我们也经常声明一种变量,它只会被使用一次,而且是用在下一行代码中,比如:
URL url = new URL("http://notes.youngkbt.cn"); URLConnection connection = url.openConnection(); Reader reader = new BufferedReader(new InputStreamReader(connection.getInputStream()));1
2
3尽管 IDEA 可以帮我们自动完成这些代码,但当变量总是跳来跳去的时候,可读性还是会受到影响,因为变量类型的名称由各种不同长度的字符组成。而且,有时候开发人员会尽力避免声明中间变量,因为 太多的类型声明只会分散注意力,不会带来额外的好处。
上面三个场景,我们想实现自动推断类型,如下:
set = new LinkedHashSet<>();
iterator = set.iterator();
url = new URL("http://notes.youngkbt.cn");
connection = url.openConnection();
reader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
2
3
4
5
但是这样又不好看,我们无法直观的知道变量的类型,于是 Java 10 提出了局部变量类型推断。
# 使用举例
Java 10 提出的局部变量类型推断和前端的 JavaScript 类似,通过 var 来实现类型推断,如下:
public void test1() {
// 1. 声明变量时,根据所附的值,推断变量的类型
var num = 10;
var list = new ArrayList<>(Integer);
list.add(123);
// 2. 遍历操作
for(var i : list){
System.out.println(i);
System.out.println(i.getClass());
}
// 3. 普通的遍历操作
for(var i = 0;i < 100;i++){
System.out.println(i);
}
}
public void test2() {
try{
var url = new URL("http://notes.youngkbt.cn");
var connection = url.openConnection();
var reader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
}catch (IOException e){
e.printStackTrace();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 不适用情况
在局部变量使用时,如下情况不适用:
初始值为 null

方法引用
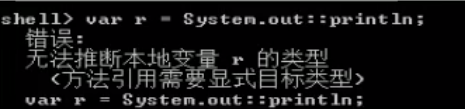
Lambda 表达式

为数组静态数组化

错误的例子:
public void test2() {
// 1. 局部变量不赋值,就不能实现类型推断
var num;
// 2. Lambda表示式中,左边的函数式接口不能声明为 var
var sup = () -> Math.random();
// 3. 方法引用中,左边的函数式接口不能声明为 var
var con = System.out:println;
// 4. 数组的静态初始化中,注意如下的情况也不可以
var arr = {1, 2, 3, 4};
}
// 5. 方法的返回类型不可以
public var method1() {
return 0;
}
// 6. 方法的参数类型不可以
public void method2(var num) {
}
// 7. 构造器的参数类型不可以
public test2(var num) {
}
// 8. 属性不可以
var num; // 这是属性,不是方法里的局部比例
// 9. catch 块
public void method3() {
try{
}catch(var e){
e.printStackTrace();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 工作原理
在处理 var 时,编译器先是查看表达式右边部分,并根据右边变量值的类型进行推断,作为左边变量的类型,然后 将该类型写入字节码当中。
注意:
var 不是一个关键字
你不需要担心变量名或方法名会与 var 发生冲突,因为 var 实际上并不是一个关键字,而是一个类型名,只有在编译器需要知道类型的地方才需要用到它。除此之外,它就是一个普通合法的标识符。也就是说,除了不能用它作为类名,其他的都可以,但极少人会用它作为类名。
这不是 JavaScript
首先我要说明的是,var 并不会改变 Java 是一门静态类型语言的事实。编译器负责推断出类型,并把结果写入字节码文件,就好像是开发人员自己敲入类型一样。
下面是使用 IntelliJ(实际上是 Fernflower 的反编译器)反编译器反编译出的代码:
从代码来看,就好像之前已经声明了这些类型一样。事实上,这一特性只发生在编译阶段,与运行时无关,所以对运行时的性能不会产生任何影响。所以请放心,这不是 JavaScript。
注意 1:局部变量类型推断是从
=右边推断左边,如果右边类型不明确,则出现编译错误。注意 2:var 不是关键字,只是语法的改进,可以
int var = 27;
# 新增不可变集合方法
自 Java 9 开始,Jdk 里面为集合(List / Set /Map)都添加了 of(JDK9 新增)和 copyOf(JDK10 新增)方法,它们两个都用来创建不可变的集合。
来看下它们的使用和区别:
public void test() {
// 示例 1
var list1 = List.of("Java", "Python", "C");
var copy1 = List.copyOf(list1);
System.out.println(list1 == copy1); // true
//示例2∶
var list2 = new ArrayList<String>();
var copy2 = List.copyOf(list2);
System.out.println(list2 == copy2); // false
// 示例 1 和 2 代码基本一致,为什么一个为 true,一个为 false?
}
2
3
4
5
6
7
8
9
10
11
12
示例 1 和 2 代码基本一致,为什么一个为 true,一个为 false?
copyOf(Xxx coll):如果参数 coll 本身就是一个只读集合,则 copyOf() 返回值即为当前的参数 coll;如果参数 coll 不是一个只读集合,则 copyOf() 返回一个新的集合,这个集合是可读的。
从源码分析,可以看出 copyOf 方法会先判断来源集合是不是 AbstractlmmutableList 类型的,如果是,就直接返回,如果不是,则调用 of 创建一个新的集合。
示例 2 因为用的 new 创建的集合,不属于不可变 AbstractlmmutableList 类的子类,所以 copyOf 方法又创建了一个新的实例,所以为 false。
注意:使用 of 和 copyOf 创建的集合为不可变集合,不能进行添加、删除、替换、排序等操作,不然会报 java.lang.UnsupportedOperationException 异常。
上面演示了 List 的 of 和 copyof 方法,Set 和 Map 接口也都有。
# 完全支持Linux和Docker容器
许多运行在 Java 虚拟机中的应用程序(包括 Apache Spark 和 Kafka 等数据服务以及传统的企业应用程序)都可以在 Docker 容器中运行。但是在 Docker 容器中运行 Java 应用程序一直存在一个问题,那就是在容器中运行 JVM 程序在设置内存大小和 CPU 使用率后,会导致应用程序的性能下降。这是因为 Java 应用程序没有意识到它正在容器中运行。随着 Java 10 的发布,这个问题总算得以解决,JVM 现在可以识别由容器控制组(cgroups)设置的约束。可以在容器中使用内存和 CPU 约束来直接管理 Java 应用程序,其中包括:
- 遵守容器中设置的内存限制
- 在容器中设置可用的CPU
- 在容器中设置CPU约束
- Java 10 的这个改进在 Docker for Mac、Docker for Windows 以及 Docker Enterprise Edition 等环境均有效
容器的内存限制:在 Java 9 之前,JVM 无法识别容器使用标志设置的内存限制和 CPU 限制。而在 Java 10 中,内存限制会自动被识别并强制执行
Java 将服务器类机定义为具有 2 个 CPU 和 2GB 内存,以及默认堆大小为物理内存的 1/4。例如,Docker 企业版安装设置为 2GB 内存和 4 个 CPU 的环境,我们可以比较在这个 Docker 容器上运行 Java 8 和 Java 10 的区别
Docker 设置堆大小
docker container run -it -m512 --entrypoint bash openjdk:latest
首先,对于 Java 8:最大堆大小为 512M 或 Docker EE 安装设置的 2GB 的 1/4,而不是容器上设置的 512M 限制。
相比之下,在 Java 10 上运行相同的命令表明,容器中设置的内存限制与预期的 128M 非常接近:
Docker 设置可用的 CPU
默认情况下,每个容器对主机 CPU 周期的访问是无限的。可以设置各种约束来限制给定容器对主机 CPU 周期的访问。Java 10 可以识别这些限制:
docker container run -it --cpus 2 openjdk:10-jdk
分配给 Docker EE 的所有 CPU 会获得相同比例的 CPU 周期。这个比例可以通过修改容器的 CPU share 权重来调整,而 CPU share 权重与其它所有运行在容器中的权重相关。此比例仅适用于正在运行的 CPU 密集型的进程。当某个容器中的任务空闲时,其他容器可以使用余下的 CPU 时间。实际的 CPU 时间的数量取决于系统上运行的容器的数量。这些可以在 Java 10 中设置:
docker container run -it --cpu-shares 2048 openjdk:10-jdk
cpuset 约束设置了哪些 CPU 允许在 Java 10 中执行。如下:
docker run -it --cpuset-cpus="1,2,3" openjdk:10-jdk
分配内存和 CPU
使用 Java 10,可以使用容器设置来估算部署应用程序所需的内存和 CPU 的分配。我们假设已经确定了容器中运行的每个进程的内存堆和 CPU 需求,并设置了 JAVA_OPTS 配置。例如,如果有一个跨 10 个节点分布的应用程序,其中五个节点每个需要 512MB 的内存和 1024 个 CPU-shares,另外五个节点每个需要 256MB 和 512 个 CPU-shares。
注意:1 个 CPU share 比例由 1024 表示:
512Mb × 5 = 2.56GB
256Mb × 5 = 1.28GB
2
对于内存,应用程序至少需要分配 5GB:
1024 x 5 = 5个CPU
512 x 5 = 3个CPU
2
最佳实践是建议分析应用程序以确定运行在 JVM 中的每个进程实际需要多少内存和分配多少 CPU。但是,Java 10 消除了这种猜测,可以通过调整容器大小以防止 Java 应用程序出现内存不足的错误以及分配足够的 CPU 来处理工作负载。
# 其他
Optional 添加了一个实例方法:orElseThrow()。如果 Optional 实例对象为空,则抛出异常 NoSuchElementException。
String s = Optional.of(null).orElseThrow(); // 抛出异常 NoSuchElementException